




2. 安徽师范大学 网络与信息安全工程技术研究中心, 安徽 芜湖 241003
2. Engineering Technology Research Center of Network and Information Security, Anhui Normal University, Wuhu Anhui 241003, China
随着定位技术的发展和智能设备的普及,产生了大量移动对象的轨迹数据,这些轨迹数据包含的非敏感信息,如朋友信息、职业信息等,促进了社交推荐[1-4]的快速发展,例如为用户提供饭店推荐服务时,考虑用户与朋友兴趣选择更相似,对用户轨迹和朋友信息发布进行数据挖掘来提高推荐质量;当预测用户未来轨迹位置时,考虑相同职业的用户轨迹可能更相似,对用户轨迹和职业信息发布进行数据挖掘来提高预测精度等。然而,简单地将移动对象轨迹和非敏感信息发布进行社交推荐时,若攻击者掌握用户的部分轨迹序列和非敏感信息,可能形成隐秘位置推理攻击[5],造成用户隐私信息的泄露,例如攻击者掌握用户的部分轨迹序列和朋友关系,则可以根据朋友信息高概率推测出用户的轨迹信息,从而威胁用户的安全。因此,用户轨迹数据的隐私保护发布成为研究者和用户的关注重点。
目前,轨迹数据隐私保护发布的研究方法主要集中于K-匿名模型[6],已取得大量研究成果[7-14]。近年来,随着高维轨迹数据集隐私保护发布[15]的提出,由于传统的隐私保护算法并不适用于高维轨迹数据集的隐私保护[15-16],相关领域也取得了很多研究成果[15-21]:Mohammed等[15]基于LKC-隐私模型[20](其中K表示轨迹匿名个数,C表示敏感信息推断概率,L表示轨迹序列长度)获得高维轨迹数据集中所有存在隐私泄露的违反序列,提出全局抑制违反序列的隐私保护算法;Chen等[16]在文献[15]的研究基础上,考虑全局抑制操作会删除大量的数据实例,提出局部抑制违反序列来消除隐私泄露,保证数据集的数据后续实用性;Al-Hussaeni等[17]基于轨迹前缀树提出动态更新轨迹序列滑动窗口的隐私模型,能解决轨迹数据流发布造成的用户隐私泄露问题;Ghasemzadeh等[18]基于LK-隐私模型(其中K表示轨迹匿名个数,L表示轨迹序列长度)提出抑制轨迹序列操作来消除轨迹数据集用于客流分析时造成的用户位置隐私泄露问题;Komishani等[19]提出基于轨迹数据隐私水平和敏感属性分类树水平来泛化敏感属性的隐私保护算法,能解决轨迹序列造成的隐私泄露问题。
现有的轨迹隐私保护方法大多应用于解决轨迹数据发布过程中轨迹序列造成的位置隐私泄露和敏感信息泄露两方面问题,而针对轨迹数据和非敏感信息联合发布过程中存在的隐私泄露问题[15-16]并未见研究工作。简单使用上述隐私保护算法解决该问题存在如下缺陷:若对非敏感信息进行泛化处理[21-23],轨迹数据集高维性使得处理后的非敏感信息实用性得不到保证;若不对非敏感信息进行泛化处理,当轨迹序列在部分非敏感信息下存在隐私泄露、在部分非敏感信息下不存在隐私泄露时,算法总是抑制数据集中全部轨迹序列,造成实例被大量抑制,处理后的实例实用性得不到保证。
为此,本文提出基于非敏感信息分析的轨迹数据隐私保护发布算法(Trajectory Privacy-preserving based on Non-Sensitive information Analysis,TP-NSA)。首先针对高维轨迹数据集和非敏感信息联合存在的隐私泄露问题,构建LQK-隐私模型(其中L表示轨迹序列长度,Q表示非敏感信息集合,K表示轨迹匿名个数)获取数据集在各非敏感信息下可能存在隐私泄露的违反序列元组集合;然后基于各时序序列的抑制方式提出非敏感信息下各时序序列的抑制权重值计算公式,并依据权重值对违反序列元组集合进行抑制处理操作,得到满足LQK-隐私模型的匿名轨迹数据集。本文对包含违反序列的轨迹数据进行局部抑制操作时,采用双重判断:一是权重值最高;二是借鉴公共子序列的思想,选择各轨迹中可以消除最多违反序列元祖的时序序列作为抑制成员,保证轨迹数据的后续实用性。
1 相关定义及隐私模型 1.1 相关定义定义1 轨迹[7]。轨迹是三维空间中时间和位置有序组合得到的连续线段,可形式化表示为tr=(oi;((x1,y1,t1),(x2,y2,t2),…,(xn,yn,tn)))。其中:oi为用户标识;((x1,y1,t1),(x2,y2,t2),…,(xn,yn,tn))为轨迹序列,且t1<t2<…<tn,(xi,yi,ti)为时序序列,表示移动对象在ti时刻的位置为(xi,yi);|tr|为轨迹的长度,即轨迹中不同时序序列的个数。
定义2 轨迹连接[15]。已知轨迹tr1=((x11,y11,t11),(x21,y21,t21),…,(xi1,yi1,ti1)),轨迹tr2=((x12,y12,t12),(x22,y22,t22),…,(xj2,yj2,tj2)),且|tr1|=|tr2|,则tr1和tr2可以连接当且仅当(x11,y11,t11)=(x12,y12,t12),(x21,y21,t21)=(x22,y22,t22),…,(xi-11,yi-11,ti-11)=(xj-12,yj-12,tj-12),ti1<tj2,连接后得到的新轨迹为tr=((x11,y11,t11),(x21,y21,t21),…,(xi-11,yi-11,ti-11),(xi1,yi1,ti1),(xj2,yj2,tj2))),记作tr=tr1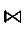
定义3 序列相交。已知序列集合q1={(x11,y11,t11),(x21,y21,t21),…,(xi1,yi1,ti1)},序列集合q2={(x12,y12,t12),(x22,y22,t22),…,(xj2,yj2,tj2)},则q1和q2相交当且仅当q1∩q2!=∅。
定义4 轨迹数据。轨迹数据是移动用户所有个人信息的集合。通常情况下,轨迹数据表示为Tr=(oi;((x1,y1,t1),(x2,y2,t2),…,(xn,yn,tn));ns1,ns2,…,nsm),其中Q为非敏感信息(non-sensitive, ns)集合,nsi∈Q(1≤i≤m)。
定义5 轨迹数据集[15]。轨迹数据集T是一系列轨迹数据的集合,表示为:T=(tr1,tr2,…,trn)。
1.2 LQK-隐私模型对移除用户标识符后发布的轨迹数据集进行信息挖掘时,攻击者可以获取用户的轨迹序列和非敏感信息作为背景知识来攻击用户。本文在轨迹序列与非敏感信息联合攻击造成的隐私泄露问题上提出LQK-隐私模型。
定义6 LQK-隐私模型。假设L为攻击者掌握用户的背景知识(即轨迹序列个数)最大长度,Q为非敏感信息集合,K为轨迹匿名个数,则轨迹数据集满足LQK-隐私模型当且仅当长度0<|q|≤L的轨迹序列q满足:对Q中各ns,|T({q,ns})|≥K,其中T({q,ns})表示数据集同时包含q和ns的轨迹集合,|T({q,ns})|表示数据集同时包含q和ns的轨迹个数,要求轨迹个数至少K条。
定义7 违反序列元组。假设q为轨迹数据集上满足0<|q|≤L的轨迹序列,给定LQK-隐私模型,若Q中存在ns满足|T({q,ns})|<K,则称{q,ns}为违反序列元组。
定义8 最小违反序列元组。给定{q,ns},若q的所有可能子序列[15]与ns组合都不是违反序列元组,称{q,ns}为最小违反序列元组(Minimal Violating Sequence tuple,MVS),记作mMVS,并将数据集中存在的所有mMVS存储到集合MMVS中。
定义9 权重值(Weight)。q的权重值是评价时序序列q在非敏感信息下抑制造成的信息损失指标,记为w(q)。计算公式如下:
| $w(q)=mvsDel(q)/inf oLoss(q)$ | (1) |
其中:mvsDel(q)表示MMVS中包含q的违反序列元组个数;infoLoss(q)表示抑制q造成轨迹和非敏感信息关联性的缺失率,按式(2) 计算。
| $inf oLoss(q)=\sum\limits_{i=1}^{n}{\frac{loss(i)}{count(i)}}$ | (2) |
其中:count(i)表示数据集同时包含q与第i个ns的轨迹个数,loss(i)表示抑制操作造成同时包含q和第i个ns的轨迹减少数量,n为非敏感信息个数。
2 隐私保护算法本文提出的TP-NSA算法主要用于解决轨迹序列和非敏感信息联合造成的隐私泄露问题,核心思想是对数据集在各非敏感信息下存在隐私泄露的违反序列元组进行抑制操作,保证轨迹K-匿名,同时尽可能保证匿名数据集的后续实用性。因此,基于文献[16]的LKC-Local(Length K-anonymity Confidence based on Local suppression)算法框架,本文的TP-NSA算法分为两个步骤:1) 获取轨迹数据集最小违反序列元组集合;2) 对最小违反序列元组进行时序序列抑制方式判断和时序序列抑制选择,从而进行轨迹数据集匿名化处理。
2.1 相关定理及证明定理1 LQK-隐私模型是有效的。
证明 文献[15]指出高维轨迹数据集的高维性和数据稀少造成实现传统K-匿名需要花费极大代价,因此高维轨迹数据集隐私保护研究需要限制攻击者掌握的背景知识长度L;同时从定义6得出:LQK-隐私模型可以保证用户轨迹在轨迹序列和非敏感信息联合下被成功识别的概率≤1/K,故LQK-隐私模型是有效的。 证毕。
定理2 TP-NSA算法采用公共子序列实现数据低损失是可行的。
证明 文献[24]指出:数据集中实例个数和MFS(Maximal Frequent Sequence)[24]个数对数据挖掘质量影响较大,而公共子序列可以作为描述多个违反序列元组公共包含的时序序列,对该时序序列进行抑制操作,可以同时消除多个违反序列元组造成的隐私泄露问题,降低实例抑制个数,实现数据集的数据低损失。故TP-NSA算法采用公共子序列实现数据低损失是可行的。 证毕。
2.2 TP-NSA算法描述 2.2.1 最小违反序列元组获取在获取数据集各非敏感信息下存在隐私泄露的违反序列元组时,由于LKC-Local算法[16]提出的MVS生成子算法并没有将非敏感信息当成违反序列一部分,而且若对每个非敏感信息进行一次数据集扫描,花费时间代价较大。因此,本文基于文献[16]的MVS生成子算法框架提出改进的MVS生成算法(具体见算法1) :首先将非敏感信息相同的轨迹放在同一个等价类Tns中(见算法1第2) ~9) 行),用于算法的后续操作,从而保证对所有非敏感信息进行扫描操作次数总和为数据集记录个数,减少扫描花费时间。然后根据定义6对各等价类Tns进行扫描判断:若在违反序列候选集合Di中存在轨迹序列q满足|T({q,ns})|<K,则表明{q,ns}元组会泄露用户的位置隐私,将{q,ns}当成违反序列元组存入MVSns集合中(见算法1第15) ~16) 行);若不存在,则将Di中轨迹序列存到NMVSi集合(见算法1第18) 行),用于序列连接得到下一个违反序列候选集合Dj(见定义2) 。重复上述操作,直到违反序列候选集合为空且背景知识长度达到阈值L时结束Tns扫描。另外,算法总是对每次序列连接得到的候选集合进行去除父序列操作[15](见算法1第23) ~27) 行),缩小违反序列候选集合,减少查找时间。具体描述如下:
算法1 MVS Generating。
输入 T, L,K, Q;
输出 MMVS,Tec。
1) MMVS←∅;Tec←∅;i←1;
2) for each ns∈Q do //非敏感信息轨迹划分
3) for each trajectory tr∈T do
4) if tr has the same ns
5) Tns← Tns∪{tr};
6) end if;
7) end for;
8) Tec←Tec∪{Tns};
9) end for;
10) D1=all distinct doublets in T;
11) for each Tns∈Tec
12) if i <=L and Di!=∅ then
13) for each sequence q∈Di do
14) scan Tns to compute|T({q,ns})|;
15) if |T({q,ns})|<K then
16) MVSns←MVSns∪{q,ns};
17) else
18) NMVSi ← NMVSi∪{q};
19) end if;
20) end for;
21) i++;
22) Di=NMVSi-1 NMVSi-1;
23) for each sequence q∈Di do
24) if {q,ns} is a super sequence of m∈MVSns then
25) remove q from Di;
26) end if;
27) end for;
28) else
29) MMVS←MMVS∪MVSns;
30) i←1;
31) end if;
32) end for;
33) return MMVS,Tec;
2.2.2 匿名化处理对于给定的轨迹数据tr和包含q的违反序列元组m,有效选择违反序列元组中抑制时序序列,可以降低数据集实例抑制个数。算法2基于公共子序列思想详细描述违反序列元组中抑制时序序列的选择,首先将MMVS包含于tr的违反序列元组存到集合A中;然后将A中与m相交的违反序列元组m′存到集合B(见定义3) ;最后对m分割得到长度为1的时序序列集合C,扫描集合B计算C中各时序序列的父序列[15]个数作为在tr中得分,并返回得分最高的时序序列。这样,抑制最高分时序序列可以保证轨迹在损失最少实例情况下,得到更多的隐私保护,数据实用性更高。
算法2 Suppression-doublet Checking。
输入 tr, an MVS m that contains q;
输出 the suppression doublet in m。
1) A←{m′|m′∈tr,m′∈MMVS};
2) B←{m′|m′∈A,m∩m′≠∅};
3) C=all distinct doublets in m;
4) for each doublet q′∈C do
5) Scan B to compute |q′|;
6) D=D∪|q′|;
7) end for;
8) select the doublet q′ with highest score from D;
9) if q′ equals q then
10) return q;
11) else
12) return q′;
13) end if;
算法在判断违反序列元组中各时序序列的抑制方式时,考虑LKC-Local算法[16]为时序序列抑制方式的判断设计了高效的判定方法,并证明了方法的有效性,因此,本文直接调用该方法来获取各时序序列在非敏感信息下的抑制方式。
确定MVS中时序序列抑制方式集合suppression_way之后,根据定义9提出的权重值计算公式,得到MVS中时序序列在非敏感信息下的抑制权重表Weight_Table,并按照降序排列。考虑权重值大小反映出用户隐私获取与信息损失之间的比值,权重值越大,表明比值越大,数据损失越小,因此算法3总是选择权重值最高的时序序列q作为抑制成员,并根据q抑制方式的不同对各等价类Tns采取不同的操作(见算法3第5) ~15) 行):如果q可以局部抑制,选择包含最小违反序列元组m(m包含q)的轨迹tr进行q抑制操作时,算法并不是直接对tr中q抑制,而是调用算法2得到m中最高分抑制时序序列q′,并执行q′抑制操作(见算法3第9) ~10) 行),因为基于算法2得到的抑制时序序列包含于违反序列元组最多,这样每次抑制操作可以实现tr中违反序列元组消除最多,从而保证数据损失最小;如果q被全局抑制,则抑制Tns中所有q(见算法3第14) 行)。此外,当q引起的隐私泄露消除后,算法需要更新MVS,检查时序序列的抑制方式是否发生改变,更新和降序排列Weight_Table,为下一次抑制作准备(见算法3第16) ~17) 行)。
重复上述操作直到Weight_Table为空时结束,将抑制处理得到的数据集作为可以发布的匿名数据集T′。
算法3 Anonymity Processing。
输入 Tec,MMVS,suppression_way, Weight_Table;
输出 满足LQK-隐私模型的轨迹数据集T′。
1) T′←∅;
2) while Weight_Table ≠ ∅ do /*迭代抑制各时序序列*/
3) q←the first doublet in Weight_Table;
4) for each Tns∈Tec do
5) if suppression_way(q)=local suppression then
6) for each m∈MVSns (q) do
7) A←{tr|tr∈Tns,m⊂tr};
8) for each trajectory tr∈A do
9) q′←Suppression-doublet Checking(tr,m);
10) Delete q′ from tr;
11) end for;
12) end for;
13) else
14) Delete all q from Tns;
15) end if;
16) MMVS=MMVS-MVSns (q);
17) Update the w(q′) if q′ in MVSns (q);
18) T′←T′∪{Tns};
19) end for;
20) Remove q from Weight_Table;
21) end while;
22) return T′;
2.3 算法分析TP-NSA算法时间复杂度由两部分组成。第一部分是获取数据集中违反序列元组集合,这部分花费时间的操作是扫描数据集判断轨迹序列在各非敏感信息下的隐私泄露风险,由于轨迹数据集中轨迹序列候选集合大小为O(|d|2)[15],算法1对各轨迹序列在各非敏感信息下进行扫描操作的时间复杂度为O(|d|2|T|),其中|d|为轨迹数据集的维数,|T|为轨迹数据集的记录数。第二部分是对算法1产生的MVS集合进行抑制处理,假设算法1产生的MVS集合大小为O(N),算法3执行次数为O(M),每个MVS包含于轨迹集合的平均个数为O(L),则算法3每次抑制操作消除MVS个数为O(N/M),花费时间为O(L/MN2)。考虑判断时序序列在非敏感信息下的局部抑制有效性的时间复杂度为O(N|T|)[16],因此,TP-NSA算法的总时间复杂度为O(|d|2|T|)+O(M)·O(L/MN2)+O(N|T|)=O(|d|2|T|)+O(LN2)+O(N|T|),其中:|d|为轨迹数据集的维数,|T|为轨迹数据集的记录数。
TP-NSA算法与LKC-Local算法[16]相比,在轨迹序列隐私泄露判定时,将非敏感信息轨迹进行等价类划分,能缩短算法扫描花费时间;在序列抑制操作时,采用公共子序列的思想,能降低数据实例的抑制数量。
2.4 衡量标准损失率是衡量轨迹数据集数据实用性的重要参数。基于高维轨迹数据集挖掘处理时实例个数和MFS[24]个数对挖掘价值的影响[15-16],本文将从实例和MFS两方面衡量TP-NSA算法实用性损失:
1) 在实例损失[16]方面,采用式(3) 来衡量:
| $InstanceLoss=\left[ N(T)-N({{T}^{'}}) \right]/N(T)$ | (3) |
其中,N(T)和N(T′)分别表示原始轨迹数据集中实例总数和匿名轨迹数据集中实例总数。实例损失越小,表明匿名轨迹数据集与原始轨迹数据集的相似度越大,数据挖掘操作得到的挖掘结果越精确。
2) 在MFS损失[16]方面,使用文献[24]提出的MAFIA算法分别得到原始轨迹数据集MFS集合和匿名轨迹数据集MFS集合,并采用式(4) 来衡量:
| $MFSLoss=\left[ U(T)-U({{T}^{'}}) \right]/U(T)$ | (4) |
其中,U(T)和U(T′)分别表示原始轨迹数据集MFS总数和匿名轨迹数据集MFS总数。MFS损失越小,表明基于MFS进行数据挖掘为用户提供推荐服务的质量越高,用户满意度越高。
3 实验与分析 3.1 实验数据集实验采用合成数据集City80K[15-16, 19]来测试TP-NSA隐私保护算法数据实用性损失。City80K是一个模拟拥有26个板块的大都市中80 000个行人在每天24小时移动轨迹的合成数据集,其中数据集提供的非敏感信息为用户职业信息,包括医生、学生和律师三种。实验的硬件环境为:Intel Core2 Quad CPU Q9500 @2.83 GHz,2 GB内存,操作系统为Microsoft Windows 7,算法使用Java语言实现。
3.2 实验结果与分析基于2.4节的实例损失和MFS损失衡量标准,本文将TP-NSA算法与基于传统K-匿名[6]的Trad-Local算法和文献[16]提出基于局部抑制的LKC-Local算法进行比较,图 1~3展示了三个算法的实例损失率和MFS损失率对比结果。

|
图 1 实例损失(L=3) Figure 1 InstanceLoss (L=3) |

|
图 2 MFS损失vs.K (L=3) Figure 2 MFSLoss vs.K (L=3) |

|
图 3 实用性损失vs.L (K=30,S=800) Figure 3 UtilityLoss vs. L (K=30,S=800) |
图 1是L值相同、K值不同情况下实例损失率的对比结果。实验中TP-NSA和LKC-Local设定L=3,Trad-Local设定L=|d|(|d|表示轨迹数据集维数),K从20递增到40。从图 1中可看出,实例损失率随着K的递增而递增,且TP-NSA算法的实例损失率低于LKC-Local算法,这是由于K的递增使得违反序列元组递增,被抑制序列个数递增,实例损失率递增。但TP-NSA算法不仅考虑轨迹序列在各非敏感信息下的隐私泄露风险,而且违反序列元组抑制时也考虑局部抑制最优的时序序列,能降低实例被错误抑制的概率,保证数据集实例可用性;Trad-Local算法则受限于背景知识的最大长度为数据集维数,各非敏感信息下的违反序列元组比较多,实例损失率最高。
图 2是L值相同、K值和S值不同的情况下MFS损失率的对比结果。实验中TP-NSA和LKC-Local设定L=3,Trad-Local设定L=|d|(|d|表示轨迹数据集维数),K从20递增至35,S从200递增至1 000。
从图 2中可以看出,在相同S值的情况下,MFS损失率随着K的递增而递增,这时由于K的递增导致违反序列元组的个数递增,被抑制的序列递增,数据集中MFS损失率越来越大;在相同K值的情况下,MFS损失率随着S的递增先递增后递减,这是由于S的递增使得MFS个数降低,且MFS与MVS之间的覆盖率逐渐递减,造成损失率先递增再递减。由对比实验可以看出,TP-NSA算法在不同参数K上和S上MFS损失率都要低于LKC-Local算法,因为LKC-Local算法在处理轨迹序列和非敏感信息联合攻击造成的隐私泄露问题时,认为轨迹序列在非敏感信息下存在隐私泄露风险时,则数据集全部抑制该违反序列,造成很多时序序列被错误抑制;TP-NSA算法则将非敏感信息当作违反序列元组一部分,只对数据集中包含相同非敏感信息的轨迹进行抑制处理,保证时序序列的低损失率;相比Trad-Local算法,轨迹数据集的高维性使得违反序列集合的相当庞大,时序序列被抑制的个数增多,MFS损失率最高。
图 3表示参数L对实例损失和MFS损失的影响。实验中固定K=30,S=800,参数L的取值从1增加到5。
从图 3可以看出:实例损失率和MFS损失率随着参数L的递增而递增。L的递增导致存在隐私泄露的违反序列元组越来越多,被抑制的序列越来越多,导致实例损失率和MFS损失率递增。由对比实验可以看出,TP-NSA算法的实例损失率和MFS损失率低于LKC-Local算法。当L比较小时违反序列很少,由于MVS集合相同造成两种算法在实例损失率和MFS损失率相等;而随着L的递增,违反序列个数逐渐递增,非敏感信息的限制有效减少了数据集实例的抑制个数,使得TP-NSA算法在实例损失率和MFS损失率上低于LKC-Local算法。
4 结语本文基于攻击者背景知识的实际假设,针对使用用户移动轨迹和非敏感信息进行数据挖掘以提供社交推荐服务会对高维轨迹数据集发布造成用户隐私泄露的问题,提出了一种基于非敏感信息分析的轨迹数据隐私保护发布算法——TP-NSA算法。该算法引入LQK-隐私模型来获取轨迹数据集在非敏感信息限制下可能存在隐私泄露的轨迹序列,并采用局部抑制和全局抑制相结合的操作消除违反序列元组,实现轨迹数据集K-匿名。实验结果表明,TP-NSA算法在实例损失率和MFS损失率上优于LKC-Local算法和Trad-Local算法。下一阶段的研究工作是对隐私保护的发布数据集进行数据挖掘,帮助服务提供商更好地为用户提供个性化推荐服务,同时尽可能实现推荐服务过程中的隐私保护。
| [1] | KONSTAS I, STATHOPOULOS V, JOSE J M. On social networks and collaborative recommendation[C]//SIGIR'09:Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York:ACM, 2009:195-202. |
| [2] | MA H, ZHOU D, LIU C, et al. Recommender systems with social regularization[C]//WSDM'11:Proceedings of the 4th ACM International Conference on Web Search and Data Mining. New York:ACM, 2011:287-296. |
| [3] | YE M, YIN P, LEE W-C, et al. Exploiting geographical influence for collaborative point-of-interest recommendation[C]//Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York:ACM, 2011:325-334. |
| [4] | LIU B, HENGARTNER U. Privacy-preserving social recommendations in geosocial networks[C]//PST 2013:Proceedings of the 11th International Conference on Privacy, Security and Trust. Washington, DC:IEEE Computer Society, 2013:1-21. |
| [5] | 霍峥, 孟小峰, 黄毅. PrivateCheckIn:一种移动社交网络中的轨迹隐私保护方法[J]. 计算机学报, 2013, 36 (4) : 716-726. ( HUO Z, MENG X F, HUANG Y. PrivateCheckIn:trajectory privacy preserving for check-in services in MSNS[J]. Chinese Journal of Computers, 2013, 36 (4) : 716-726. ) |
| [6] | SWEENEY L. k-anonymity:a model for protecting privacy[J]. International Journal of Uncertainty Fuzziness and Knowledge Based Systems, 2002, 10 (5) : 557-570. doi: 10.1142/S0218488502001648 |
| [7] | 霍峥, 孟小峰. 轨迹隐私保护技术研究[J]. 计算机学报, 2011, 34 (10) : 1820-1830. ( HUO Z, MENG X F. A survey of trajectory privacy preserving techniques[J]. Chinese Journal of Computers, 2011, 34 (10) : 1820-1830. doi: 10.3724/SP.J.1016.2011.01820 ) |
| [8] | ABUL O, BONCHI F, NANNI M. Never walk alone:uncertainty for anonymity in moving objects databases[C]//ICDE'08:Proceedings of the 2008 IEEE 24th International Conference on Data Engineering. Washington, DC:IEEE Computer Society, 2008:376-385. |
| [9] | YAROVOY R, BONCHI F, LAKSHMANAN L V S, et al. Anonymizing moving objects:how to hide a MOB in a crowd?[C]//EDBT'09:Proceedings of the 12th International Conference on Extending Database Technology:Advances in Database Technology. New York:ACM, 2009:72-83. |
| [10] | NERGIZ M E, ATZORI M, SAYGIN Y, et al. Towards trajectory anonymization:a generalization-based approach[C]//SPRINGL'08:Proceedings of the SIGSPATIAL ACM GIS 2008 International Workshop on Security and Privacy in GIS and LBS. New York:ACM, 2008:52-61. |
| [11] | TERROVITIS M, MAMOULIS N. Privacy preservation in the publication of trajectories[C]//MDM'08:Proceedings of the 9th International Conference on Mobile Data Management. Piscataway, NJ:IEEE, 2008:65-72. |
| [12] | 袁冠, 夏士雄, 张磊, 等. 基于结构相似度的轨迹聚类算法[J]. 通信学报, 2011, 32 (9) : 103-110. ( YUAN G, XIA S X, ZHANG L, et al. Trajectory clustering algorithm based on structural similarity[J]. Journal on Communications, 2011, 32 (9) : 103-110. ) |
| [13] | MANO K, MINAMI K, MARUYAMA H. Pseudonym exchange for privacy-preserving publishing of trajectory data set[C]//GCCE 2014:Proceedings of the 3rd IEEE Global Conference on Consumer Electronics. Piscataway, NJ:IEEE, 2014:691-695. |
| [14] | HUO Z, MENG X, HU H, et al. You can walk alone:trajectory privacy-preserving through significant stays protection[C]//Proceedings of the 17th International Conference on Database Systems for Advanced Applications, LNCS 7238. Berlin:Springer-Verlag, 2012:351-366. |
| [15] | MOHAMMED N, FUNG B C M, DEBBABI M. Preserving privacy and utility in RFID data publishing, Technical Report 6850[R]. Montreal, Canada:Concordia University, 2010. |
| [16] | CHEN R, FUNG B C M, MOHAMMED N, et al. Privacy-preserving trajectory data publishing by local suppression[J]. Information Sciences, 2013, 231 (1) : 83-97. |
| [17] | AL-HUSSAENI K, FUNG B C M, CHEUNG W K. Privacy-preserving trajectory stream publishing[J]. Data & Knowledge Engineering, 2014, 94 (Part A) : 89-109. |
| [18] | GHASEMZADEH M, FUNG B C M, CHEN R, et al. Anonymizing trajectory data for passenger flow analysis[J]. Transportation Research Part C:Emerging Technologies, 2014, 39 (2) : 63-79. |
| [19] | KOMISHANI E G, ABADI M. A generalization-based approach for personalized privacy preservation in trajectory data publishing[C]//IST'12:Proceedings of the 2012 IEEE Sixth International Symposium on Telecommunications. Piscataway, NJ:IEEE, 2012:1129-1135. |
| [20] | MOHAMMED N, FUNG B, HUNG P C K, et al. Anonymizing healthcare data:a case study on the blood transfusion service[C]//KDD'09:Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York:ACM, 2009:1285-1294. |
| [21] | FUNG B C M, WANG K, YU P S, Anonymizing classification data for privacy preservation[J]. IEEE Transactions on Knowledge and Data Engineering, 2007, 19(5):711-725. |
| [22] | DeWITT D J, LeFEVRE K, RAMAKRISHNAN R. Mondrian multidimensional k-anonymity[C]//SIGMOD'06:Proceedings of the 22nd IEEE International Conference on Data Engineering. Washington, DC:IEEE Computer Society, 2006:25. |
| [23] | XIAO X, TAO Y. Personalized privacy preservation[C]//Proceedings of the 2006 ACM SIGMOD International Conference on Management of Data. New York:ACM, 2006:229-240. |
| [24] | BURDICK D, CALIMLIM M, GEHRKE J. MAFIA:a maximal frequent itemset algorithm for transactional databases[C]//Proceedings of the 17th IEEE International Conference on Data Engineering. Piscataway, NJ:IEEE, 2001:443-452. |