




2. 辽宁科技大学 应用技术学院, 辽宁 鞍山 114051
2. School of Applied Technology, University of Science and Technology Liaoning, Anshan Liaoning 114051, China
概念格是隶属数学概念和概念层次结构的应用数学领域[1]。理论上结构严谨,能形象地体现事物之间的泛化与特化关系,在空间聚类方法、病症智能诊断、Folksonomy、信息修复与文件浏览、软件演化分析、访问权限管理、命题集约简等诸多领域都有着成功的应用。概念格的构建是概念格应用的前提基础,但是一个背景中概念的个数是随着背景的尺寸指数级增长的(比如对于半序集中反额定标尺概念的个数是2|S|),这样背景稍大,概念的个数就多得无法计算。如何提高概念格的构建效率是当前研究的热点课题。
对于概念格构建的主要方法有两大类。一类是批处理概念格生成算法[2-4],其主要思想是先生成背景对应的全部概念,再由亚概念与超概念的连接关系,生成节点间的连线,进而完成概念格的构建;缺点是当增加对象时,需要重新构建概念格。另一类是渐进式概念格生成算法:1995年,Godin等[5]提出了概念格的渐进式生成算法,渐增式地插入新节点;2002年,谢志鹏等[6]提出了利用树状结构存储节点快速构建概念格的渐进式生成算法,有效地区别节点类型,缩小了父子节点的搜查范围;2004年,李云等[7-8]提出了基于属性的概念格渐进式生成算法及多概念格的横向合并算法,特别说明了属性拆分及策略对概念格构建效率的影响;2009年,刘群等[9]提出了基于对象和属性交叉渐进式概念格生成算法,解决了针对对象和属性交叉渐增更新需要重新构建概念格的问题;同年,刘耀华等[10]提出了新的区间数分解与定标算法,用来处理多种类型的扩展背景,给出了相应的扩展格生成算法,改进了区间值分解与模糊概念格的属性定标方法;2012年屈文建等[11]提出了一种利用最大秩的全1矩阵来生成概念格的算法,采用背景中最大秩全1子阵对应概念格的每个节点,通过横向、纵向扩充成对应的子格,再经合并构建整体概念格;2013年,姚佳岷等[12]提出了一种基于概念内涵、外延升降序的双序渐进式概念格合并算法,特点是在结构上较好地保留了原有信息;2014年,徐敏政等[13]引入元胞数据组织结构,将对象和属性分别与概念节点的外延和内涵同时求交,提出了双向渐进式概念格生成算法,解决了概念格构建带来的更新问题,避免了繁琐的合并过程;2015年,Zou等[14]通过确定概念格的顺序关系和寻找更新概念,提出了一种快速生成概念格的新算法。
以上的这些渐进式概念格生成算法可以随着增加对象(或者属性)而动态更新概念格,适用于记录渐增事务数据库类型的背景,且算法的效率都有不同程度的提高,但是,当构建概念格的概念数目巨大时,为避免构建时的复杂过程,有效地提高构建的效率,本文提出了一种基于内涵亏值,经由超集删除,通过剩留父概念查找其所在等价类的顶元素来生成概念格正则队列的全新方法,理论分析与实验对比论证均表明该渐增式构建算法是可行的,不仅方法简单有效,且在时间性能上比其他方法优越,构建效率更高。
1 概念格的定义及定理定义1 [15] 若U为对象的集合,M为属性的集合,I⊆U×M为U和M之间的关系,称三元组$\mathbb{K}$=(U,M,I)为形式背景,简称背景。
定义2 [15] 若$\mathbb{K}$=(U,M,I)为一个背景,A⊆U,B⊆M,
f(A)={m∈M|∀u∈A,(u,m)∈I}
g(B)={u∈U|∀m∈B,(u,m)∈I}
若f(A)=B,g(B)=A,称二元组(A,B)为形式概念,简称概念。并称A为概念(A,B)的外延,B为概念(A,B)的内涵。$\mathbb{K}$上所有概念的集合记为B($\mathbb{K}$)。
性质1[15] 若$\mathbb{K}$=(U,M,I)为一个背景,A1,A2⊆U,B1,B2⊆M,则:
1) A1⊆A2 ⇒ f(A2)⊆f(A1);
2) A1⊆A2 ⇒ g(A2)⊆g(A1);
3) A1⊆g(f(A1));
4) B1⊆f(g(B1));
5) f(A1)=f(g(f(A1)));
6) g(B1)=g(f(g(B1)));
7) f(A1)∩f(A2)=f(A1∪A2);
8) g(B1)∩g(B2)=g(B1∪B2)。
定义3 [15] 设$\mathbb{K}$=(U,M,I)为一个背景,(X1,Y1),(X2,Y2)∈B($\mathbb{K}$):
1) 若X1⊆X2,称(X1,Y1)为(X2,Y2)的子概念,(X2,Y2)为(X1,Y1)的父概念,记为(X1,Y1)≤(X2,Y2)。若X1⊂X2,记为(X1,Y1)<(X2,Y2)。
2) 若(X1,Y1)<(X2,Y2),且不存在(X3,Y3),有(X1,Y1)<(X3,Y3)<(X2,Y2),则称(X1,Y1)为(X2,Y2)的直接子概念,(X2,Y2)为(X1,Y1)的直接父概念,记作(X1,Y1)$\prec $(X2,Y2),并称Y2-Y1为(X1,Y1)的一个内涵亏值。
定义4 [15] 设(M,≤)是一个半序集,若M中任何两个元素都有上确界和下确界,则称(M,≤)为一个格。
设$\mathbb{K}$0=(U,M,I),若增加一个对象u,它具有的属性集合为B,形成了新背景$\mathbb{K}$1=(U1,M1,I1),其中U1=U∪{u},M1=M,I1=I∪{u}×B。在$\mathbb{K}$0的概念格B($\mathbb{K}$0)中定义关系R,若B($\mathbb{K}$0)中有两个概念(C,D),(E,F)满足R关系,当且仅当D∩B=F∩B,显然R为等价关系(满足自反性、对称性、传递性),R在B($\mathbb{K}$0)中形成了等价类[16]。
定义5 若每个等价类[(C,D)]R都有最大元素(g(D∩B),f(g(D∩B))),称其为该等价类的顶元素。B($\mathbb{K}$0)中所有顶元素的集合为B($\mathbb{K}$0)的一个子格,称为顶元素子格。
例1 如表 1所示,背景$\mathbb{K}$1为在$\mathbb{K}$0的基础上增加一个对象u=6,具有属性的集合为B=abdh。B在B($\mathbb{K}$0)中产生的等价类如图 1中的闭曲线所示。这些等价类的顶元素分别是#1、#2、#4、#6、#7、#9、#11概念,形成的顶元素子格如图 2所示。$\mathbb{K}$0增加对象u=6后的背景$\mathbb{K}$1的概念格如图 3所示。其中,表 1用一个矩形表格表示背景,它的每一行是一个对象,每一列是一个属性,例如1行a列的交叉处是符号“×”,则表示对象1具有属性a,再如1行c列的交叉处是“-”,则表示对象1不具有属性c。
| 表 1 在$\mathbb{K}$0的基础上增加对象u=6后得到的背景$\mathbb{K}$1 Table 1 Formal context $\mathbb{K}$1 formed by adding u=6 to original context $\mathbb{K}$0 |

|
图 1 B=abdh在概念格B($\mathbb{K}$0)中形成的等价类 Figure 1 Equivalent classes formed by B=abdh in B($\mathbb{K}$0) |

|
图 2 B($\mathbb{K}$0)的顶元素子格 Figure 2 Top element sublattice of B($\mathbb{K}$0) |
在背景$\mathbb{K}$0的基础上求背景$\mathbb{K}$1时,分3种情况:
1) B($\mathbb{K}$0)中的非顶元素,例如图 1中的#3、#5、#8、#10、#12概念,它们仍为B($\mathbb{K}$1)的元素,称其为旧概念。它们在B($\mathbb{K}$1)中的直接父概念与其在B($\mathbb{K}$0)中的直接父概念具有相同的内涵。例如图 1中的#8概念,它的直接父概念是#4及#5,其内涵分别为bh与ch;而它在图 3B($\mathbb{K}$1)中的两个直接父概念仍为#4及#5,其内涵仍为bh与ch,但其直接父概念#4的外延与在B($\mathbb{K}$0)中却不一样。

|
图 3 背景$\mathbb{K}$1的概念格 Figure 3 Concept lattice of formal context $\mathbb{K}$1 |
2) 若B($\mathbb{K}$0)中的顶元素(X,Y),满足Y⊆B,则在B($\mathbb{K}$1)中概念(X∪{u},Y)称为产生概念。(X∪{u},Y)在B($\mathbb{K}$1)中的直接父概念与(X,Y)在B($\mathbb{K}$0)中的直接父概念具有相同的内涵。例如图 3中的#1、#2、#4、#7概念分别是由图 1中的#1、#2、#4、#7概念产生的。图 3中的#1、#2、#4、#7概念的父概念与图 1中的#1、#2、#4、#7概念的父概念具有相同的内涵。
3) 若B($\mathbb{K}$0)中的顶元素(X,Y),满足Y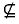
当某个(X1,Y1)也是(X∪{u},Y∩B)的直接父概念时,则应将其从(X,Y)的直接父概念集合中删除。例如图 3中#11概念,在B($\mathbb{K}$1)中与其原直接父概念有相同内涵的概念是#7、#8和#9,且在B($\mathbb{K}$1)中#7概念是新概念#15的直接父概念,所以在B($\mathbb{K}$1)中应将#7概念从#11概念的直接父概念集合中删除。删除的直接父概念连线在图 3中用虚线画出。
2 内涵亏值定义6 将概念及其内涵亏值表示成(#t,X,Y,W),其中:X为外延;Y为内涵;#t中的t为自然数,是生成概念时依次赋予的概念号;W={#t1:S1,…,#tk:Sk}为(X,Y)的内涵亏值集合,其中#ti:Si表示#ti概念为(X,Y)的一个直接父概念,Si(i=1,2,…,k)表示#ti对(X,Y)的内涵亏值。
定理1 若(X,Y)的内涵亏值集合为Δ(X,Y)={S1,S2,…,Sk},且S1∩B,S2∩B,…,Sk∩B都不空,则(X,Y)是顶元素;若存在某个Si∩B=∅,则(X,Y)不是顶元素,且与Si对应的直接父概念属于同一个等价类。
证明 若(X,Y)是顶元素,则它的任意一个直接父概念(Xi,Yi),有Y∩B⊃Yi∩B,所以对于内涵亏值Si=Y-Yi,必有Si∩B=(Y-Yi)∩B=(Y∩B)-(Yi∩B)≠∅,反之若Si∩B=∅,则Si对应的直接父概念(Xi,Yi),必有(Y-Yi)∩B=∅,即Y∩B=Yi∩B,所以(X,Y)不是顶元素,且与Si对应的直接父概念属于同一个等价类。
定义7 将概念排成正则队列,所谓正则队列,即在这个队列中任何父概念都不出现在其子概念的后面。
例2 如图 1所示,B($\mathbb{K}$0)中的概念已排成正则队列,即队列#1、#2、#4、#7、#10、#3、#5、#8、#6、#9、#11、#12是一个正则队列。计算B($\mathbb{K}$1)时,把情况3) 中的新概念(X∪{u},Y∩B)插在产生子概念(X,Y)之前,则得到的仍为正则队列。因为情况1) 中的旧概念,情况2) 中的产生概念,及情况3) 中的产生子概念(X,Y)的内涵都仍是B($\mathbb{K}$0)中的内涵,所以按B($\mathbb{K}$0)正则队列的次序排列;而新概念(X∪{u},Y∩B)的父概念全是由产生子概念(X,Y)在顶元素格中的父概念产生的,都将排在新概念(X∪{u},Y∩B)之前。即背景增加(6,abdh)后,将新概念#13、#14、#15分别插在产生它们的概念#6、#9、#11紧邻的前面,形成了B($\mathbb{K}$1)的正则队列:#1、#2、#4、#7、#10、#3、#5、#8、#13、#6、#14、#9、#15、#11、#12。
用L存放B($\mathbb{K}$0)的正则队列,用L1存放B($\mathbb{K}$1)的正则队列。在正则队列L中依次取元素(#t,X,Y,W),按下面方法1) 、2) 、3) 生成B($\mathbb{K}$1)中的元素,并逐步形成B($\mathbb{K}$1)的正则队列L1。
1) 若其内涵亏值集合W中有某个内涵亏值与B的交为∅,则在B($\mathbb{K}$1)中有旧概念(#t,X,Y,W)。
2) 若其内涵亏值集合W中所有亏值与B的交都不为∅,且Y⊆B,则在B($\mathbb{K}$1)中有产生概念(#t,X∪{u},Y,W)。
3) 若其内涵亏值集合W中所有亏值与B的交都不为∅,且Y
为了求新概念(X∪{u},Y∩B)的内涵亏值,需求出(X,Y)在顶元素格中的各个直接父概念。为此有:
定理2 若(X,Y)与(X1,Y1)为B($\mathbb{K}$0)的两个顶元素,且在顶元素格中(X1,Y1)为(X,Y)的直接父概念,则在B($\mathbb{K}$0)中存在(X,Y)的直接父概念(X2,Y2)使Y2∩B=Y1∩B。
证明 因为顶元素(X,Y)与(X1,Y1)分别为等价类[(X,Y)]θ与[(X1,Y1)]θ的最大元素,所以有Y=f(g(Y∩B)),Y1=f(g(Y1∩B))。又因为在顶元素格中(X1,Y1)为(X,Y)的直接父概念,所以有Y1∩B⊂Y∩B,于是f(g(Y1∩B))⊆f(g(Y∩B)),即Y1⊆Y。然而Y1∩B⊂Y∩B,有Y1≠Y,所以Y1⊂Y,即(X1,Y1)也是(X,Y)的父概念,于是必有一个(X,Y)的直接父概念(X2,Y2)满足Y1⊆Y2⊂Y,有Y1∩B⊆Y2∩B⊆Y∩B,但因为(X1,Y1)在顶元素子格中是(X,Y)的直接父概念,所以有Y2∩B=Y1∩B或者Y2∩B=Y∩B。由于(X,Y)也是顶元素,有Y2∩B≠Y∩B,所以Y2∩B=Y1∩B。
由定理1、定理2可知,(X1,Y1)为(X,Y)在顶元素子格中的直接父概念的必要条件是存在(X,Y)的直接父概念(X2,Y2)在(X1,Y1)的等价类中。例如如图 2所示,在顶元素格中#2概念与#6概念为#9概念的直接父概念,而在图 1中,#9概念有直接父概念#5概念,它与#2概念在同一个等价类中,#9概念有直接父概念#6概念,它与#6概念在同一个等价类中。于是B($\mathbb{K}$0)中的(X,Y)在顶元素格中的直接父概念(X1,Y1)必为(X,Y)在B($\mathbb{K}$0)中的某个直接父概念(X2,Y2)所在等价类的顶元素。
但并不是每个(X,Y)在B($\mathbb{K}$0)中的直接父概念所在等价类的顶元素都是(X,Y)在顶元素格中的直接父概念。例如如图 1所示,#11概念有三个直接父概念#7、#8、#9。而#8所在等价类的顶元素是#4,如图 2所示,它不是#11在顶元素格中的直接父概念。即若(X1,Y1)及(X2,Y2)为(X,Y)在B($\mathbb{K}$0)中的两个直接父概念,当且仅当Y1∩B⊂Y2∩B,即(Y-Y1)∩B⊃(Y-Y2)∩B,则(X1,Y1)所在等价类的顶元素在顶元素格中就是(X2,Y2)所在等价类的顶元素的父概念,而不是(X,Y)在顶元素格中的直接父概念。
为了方便地鉴别(X,Y)的哪些直接父概念所在等价类的顶元素为(X,Y)在顶元素格中的直接父概念,给出如下形式化的定义。
定义8 若概念(X,Y)的亏值集合为W,B⊆M:
1) 若W=∅(最大概念的情况),则W相对于B的超集删除为∅。
2) 若W={S1,S2,…,S$\mathbb{K}$},在集合{Si∩B,Si+1∩B,…,S$\mathbb{K}$∩B}中将是其他元素的超集删除,相同的值只留一个。
称其结果为W相对于B的超集删除,简称为超集删除。称这些未被删除的内涵亏值对应的直接父概念为(X,Y)的剩留父概念。
显然剩留父概念所在等价类的顶元素为(X,Y)在顶元素格中的直接父概念。
例3 如图 1所示,#11概念的内涵亏值集合为Δ(4,abcdh)={cd,ad,ab},这些内涵亏值与B=abdh的交分别为cd∩abdh=d,ad∩abdh=ad,ab∩abdh=ab,将是其他元素超集的删除,剩下d及ab。d及ab所对应的内涵亏值为cd及ab,cd及ab所对应的直接父概念#7及#9为剩留父概念,它们所在等价类的顶元素为#11概念在顶元素格中的直接父概念。又如图 1所示,#9概念的内涵亏值集合为Δ(34,cdh)={#5:d,#6:h},这些内涵亏值与B=abdh的交分别为d∩abdh=d,h∩abdh=h,超集删除后还为d及h,d及h所对应的直接父概念是#5概念及#6概念,它们为剩留父概念。#6概念所在等价类的顶元素就是本身,#5概念所在等价类的顶元素为#2概念,由此#2概念及#6概念为#9概念在顶元素格中的直接父概念。
利用剩留父概念查找其所在等价类的顶元素方法如下。
由定理1,检查它的各个内涵亏值Si与B的交是否为∅,都不为∅,则为顶元素。若存在某个Si∩B=∅,则Si对应的直接父概念(Xi,Yi)与(X,Y)在同一个等价类中。于是对(Xi,Yi)做如上的检查,直到存在某一个概念,其内涵亏值与B的交都不为空为止,此时这个概念就是(X,Y)直接父概念所在等价类的顶元素。若某个内涵亏值Si,有Si∩B=∅,则任何一个内涵亏值Sj∩B都为它的超集,于是超集删除的结果一定是{#i:∅}。所以是否存在某个Si∩B=∅,可用超集删除的结果是否为{#i:∅}来判定。
在正则队列L1中利用剩留父概念查找其所在等价类的顶元素,由于L中非顶元素的那些概念都为旧概念,同样出现在L1中,由此在L1中也会找到顶元素(X′,Y′)。(X′,Y′)与其生成的概念(X′∪{u},Y′∩B)的内涵亏值为Y′-(Y′∩B)=Y′-B,所以Y′∩B=∅,于是继续向上找,找到概念(X′∪{u},Y′∩B),它为新概念(X∪{u},Y∩B)在B($\mathbb{K}$1)中的直接父概念。而且容易求出这个直接父概念对(X∪{u},Y∩B)的亏值:若(X,Y)对剩留父概念的内涵亏值为Si,则这个剩留父概念(Xi,Yi)的内涵为Yi=Y-Si,于是其所在等价类顶元素(X′,Y′),有Y′∩B=Yi∩B=(Y-Si)∩B,所以(X′,Y′)产生的概念(X′∪{u},Y′∩B)的内涵为(Y-Si)∩B,又因为(X,Y)产生的概念的内涵为Y∩B,所它们之间的内涵为(Y∩B)-((Y-Si)∩B)=Si∩B。
例4 如图 1所示,在B($\mathbb{K}$0)中增加对象u=6生成B($\mathbb{K}$1)。首先在队列L中依次取概念,处理到#9概念时,其内涵亏值集合为Δ(34,cdh)={#5:d,#6:h},超集删除得{#5:d,#6:h},不是{#i:∅},所以它是顶元素,又因为cdh
#9概念内涵亏值集合中的d对应的直接父概念是#5概念,由于是正则队列,所以#5概念已出现在L1中,又由于#5概念的内涵亏值集合为Δ(234,ch)={#2:c,#3:h},超集删除得{#2:∅},所以在L1中继续向上找#2概念,#2概念的内涵亏值集合为Δ(1234,h)={#1:h},超集删除得{#1:h},不是{#i:∅},所以#2概念为#14概念(346,dh)的一个直接父概念,且内涵亏值为:Si∩B=d∩abdh=d。
#9概念内涵亏值集合中的h对应的直接父概念是#6概念,由于是正则队列,所以#6概念已出现在L1中,又由于#6概念的内涵亏值集合为Δ(345,cd)={#3:d,#13:c},超集删除得{#13:∅},所以在L1中继续向上找#13概念,#13概念的内涵亏值集合为Δ(3456,d)={#1:d},超集删除得{#1:d},不是{#i:∅},所以#13概念为#14概念的一个直接父概念,且内涵亏值为:Si∩B=h∩abdh=h。
即#14概念在L1中的直接父概念有两个,#2概念及#13概念,且内涵亏值分别为:d及h。
3 概念格构建算法1) 内涵亏值集合的超集删除子程序CO(W)。
输入:W={#t1:S1,…,#tk:Sk}(允许W=∅)。其中,#ti:Si表示Si为相对于概念#ti的内涵亏值。
输出:{#tp:Sp∩B,…,#tq:Sq∩B}(允许是∅)。
方法:
If W = ∅ Then
输出∅,结束
Else
For i = 1 to k
For j = 1 to k
If i≠j,Si ∩B⊇Sj ∩B且#ti:Si未作删除标记
Then
#ti:Si作删除标记
//因为是⊇,不是⊃,所以最终相同值只留一个
Exit(j)//退出j循环
EndIf
Next(j)
Next(i)
输出{#t:S∩B|#t:S未作删除标记},结束
EndIf
其中超集删除的结果为∅与超集删除的结果为{#t:∅}不同。前者W=∅,即(X,Y)为B($\mathbb{K}$0)的最大概念,例如图 1中的#1概念;后者W≠∅,但W中有某个Si∩B=∅,即(X,Y)不是其所在等价类的顶元素,例如图 1中的#3概念、#5概念、#8概念、#10概念、#12概念。
2) 查找#t概念所在等价类顶元素的子程序Top(#t,V)。
输入:#t,V。其中,#t为概念的概念号,#V为概念的内涵亏值集合。
输出:#i,为#t所在等价类顶元素的概念号。
方法:
If V=∅ Then
输出#t,结束
//V=∅时,#t为最大概念,必为顶元素
Else
If CO(V)只有一个元素#i:∅ Then
//#t不为顶元素,且与#i在同一等价类
在L1中取概念号为#i的概念(#i,C,D,V1)
//L1为B($\mathbb{K}$1)中的正则队列
Top(#i,V1 )//再向上查找
Else
输出#t,结束
//#t为顶元素,输出#t
EndIf
EndIf
3) 添加新对象后的概念格及内涵亏值的计算ADD(L,u,B,n)。
输入:L,u,B,n。其中,L为原概念格B($\mathbb{K}$0)的正则队列,u为新对象,B为u具有的属性集合,n为最大概念号。
输出:L1。其中:L1为添加具有属性集合B的新对象u后的概念格B($\mathbb{K}$1)的正则队列。
方法:
L1:=∅
For each (#t,X,Y,W) in L by order do
WB:=CO(W)//WB中存放W超集删除的结果
If WB 仅有一个元素 #i:∅ Then
(#t,X,Y,W)送入L1队尾//#t不为顶元素,直接送入L1
Else
If Y⊆B Then
(#t,X∪{u},Y,W)送入L1队尾
//#t为顶元素,且Y⊆B,则外延加u后送L1
Else
W1:=∅
If BW≠∅ Then
Foreach (#i:Si∩B) in WB
在L1中取概念号为#i的概念(#i,C,D,V)
令W1:=W1∪{Top(#i,V):Si∩B}
Next
EndIf
n:=n+1
(#n,X∪{u},Y∩B,W1)送入L1队尾
W2:={#i:Si|(#i:Si)∈W且#i未出现在W1中}
W2:=W2∪{#n:(Y-B)}
(#t,X,Y,W2)送L1队尾
EndIf
EndIf
Next
输出L1结束。
4) 给定一个背景$\mathbb{K}$=(U,M,I),生成$\mathbb{K}$的全部概念与内涵亏值的方法如下:
L:=(#1,∅,M,∅)//L为只有一个元素(#1,∅,M,∅)的队列
n:=1
For each (u,B) in $\mathbb{K}$
ADD(L,u,B,n)
L:=L1
Next
输出L,结束。
李云等[7]提出的CLIF_A算法比文献[5]有明显的优势。对于CLIF_A算法,设B($\mathbb{K}$0)中概念的个数为m,若在B($\mathbb{K}$0)中插入概念(A,B)=(g(B),B),至多产生2g(B)个外延包含于g(B)的概念,则更新节点和新增节点的数目至多为2g(B),进而时间复杂度为O(2g(B)×m)。
对于Zou等[14]通过确定概念格的顺序关系及寻求更新概念而提出的FastAddIntent算法,设B($\mathbb{K}$0)中概念的对象个数为G,属性个数为M,产生的新概念存储于L,由于B($\mathbb{K}$0)中任意概念的下近邻数不大于M,上近邻数不大于G,构建L时的时间复杂度为T0+O(LGM2),T0为构建L过程中获取GetClosureConcept[14]的时间复杂度,估计为O(LGM2),所以,文献[14]的总体时间复杂度为O(LGM2)。
本文算法在最好的情况下(L1中全都是旧概念和产生概念),设B($\mathbb{K}$0)中概念的个数为m,有ADD(L,u,B,n)函数的循环次数为m,整个算法的循环次数为m2,则时间复杂度为O(m2)。在最坏的情况下(L1中全部是新概念和产生子概念,并且顶元素总是最大元素),有ADD(L,u,B,n)函数的循环次数为mn(n为L1中概念的个数),整个算法的循环次数为m2n。在最坏的情况下,每次运行ADD(L,u,B,n)函数,L1中都会翻倍,有$n=\sum\nolimits_{i=1}^{m}{2i=m(m+1)}$,整个算法的循环次数为m4+m3,则时间复杂度为O(m4)。所以本文算法的时间复杂度在O(m2)~O(m4)。由此可见,理论上分析时间复杂度,本文算法明显比文献[7]有优势,且不比文献[14]差。
在硬件配置为CPU Intel i3 2.40 GHz,内存为8 GB,在Visual Studio 2010的环境下,用VB.Net语言实现本文提出的概念格构建算法,与文献[14]和文献[7]算法进行了比较,随机生成20个形式背景,概念个数从50开始递增到500,变化基数为50,实验结果如图 4所示,当概念的数目小于100时,三种算法的区别并不明显,当概念的数目逐渐变大(大于150) 时,本文提出的概念格构建算法的运行时间更快,效果更优越,证明了其算法的有效性。
4 结语本文提出了一种基于内涵亏值快速构建概念格的新方法:
1) 将原概念格排成正则队列后依次取概念元素。
2) 所取概念的内涵亏值集合作超集删除。
3) 由定理1判定,若为顶元素且元素内涵不是B的子集,则得到产生子概念与新概念;若为顶元素且元素内涵是B的子集,则得到产生概念。
4) 由定理1判定,若不为顶元素,经由剩留父概念继续向上查找,查找其所在等价类的顶元素,逐步生成新概念格的正则队列。

|
图 4 三种算法运行时间对比 Figure 4 Executing time comparison of three algorithms |
同时给出了概念格构建的算法。三种算法实验结果的对比,表明本文提出的方法显著提高了构建概念格的效率,为数据挖掘进一步的应用研究创造了良好的条件。
对于文章提出的方法,可以给出一些技巧使步骤简化,是进一步研究的方向。
| [1] | WILLE R. Restructuring lattice theory:an approach based on hierarchies of concepts[C]//ICFCA' 09:Proceedings of the 7th International Conference on Formal Concept Analysis. Berlin:Springer, 2009:445-470. |
| [2] | LINDIG C. Fast concept analysis[M]//Working with Conceptual Structures Contributions to ICCS 2000. Aachen, Germany:Shaker Verlag, 2000:152-161. |
| [3] | STUMME G, TAOUIL R, BASTIDE Y, et al. Fast computation of concept lattices using data mining techniques[C]//Proceedings of the 7th International Workshop on Knowledge Representation Meets Databases.[S.l.]:VLDB Endowment, 2010:129-139. |
| [4] | 陈震, 张娜, 王甦菁. 一种基于概念矩阵的概念格生成算法[J]. 计算机科学, 2010, 37 (9) : 180-183. ( CHEN Z, ZHANG N, WANG S J. New algorithm of generating concept lattice based on concept-matrix[J]. Computer Science, 2010, 37 (9) : 180-183. ) |
| [5] | GODIN R, MISSAOUI, R, ALAOUI H. Incremental concept formation algorithm based on Galois (concept) lattices[J]. Computational Intelligence, 1995, 11 (2) : 246-267. doi: 10.1111/coin.1995.11.issue-2 |
| [6] | 谢志鹏, 刘宗田. 概念格的快速渐进式构造算法[J]. 计算机学报, 2002, 25 (5) : 490-496. ( XIE Z P, LIU Z T. A fast incremental algorithm for building concept lattice[J]. Chinese Journal of Computers, 2002, 25 (5) : 490-496. ) |
| [7] | 李云, 刘宗田, 沈夏炯, 等. 基于属性的概念格渐进式生成算法[J]. 小型微型计算机系统, 2004, 25 (10) : 1768-1771. ( LI Y, LIU Z T, SHEN X J, et al. Attribute-based incremental formation algorithm of concept lattice[J]. Journal of Chinese Computer Systems, 2004, 25 (10) : 1768-1771. ) |
| [8] | 李云, 刘宗田, 徐晓华, 等. 多概念格的横向合并算法[J]. 电子学报, 2004, 32 (11) : 1849-1854. ( LI Y, LIU Z T, XU X H, et al. Horizontal union algorithm of multiple concept lattices[J]. Acta Electronica Sinica, 2004, 32 (11) : 1849-1854. ) |
| [9] | 刘群, 冷平, 孙凌宇. 基于对象和属性交叉的渐进式概念格生成算法[J]. 计算机工程, 2009, 35 (7) : 59-60. ( LIU Q, LENG P, SUN L Y. Incremental concept lattice formation algorithm based on alternate object and attribute[J]. Computer Engineering, 2009, 35 (7) : 59-60. ) |
| [10] | 刘耀华, 周文, 刘宗田. 一种区间数分解与定标算法及其扩展形式背景的概念格生成方法[J]. 计算机科学, 2010, 37 (9) : 180-183. ( LIU Y H, ZHOU W, LIU Z T. Interval scaling algorithm and its concept lattice construction from extended formal context[J]. Computer Science, 2010, 37 (9) : 180-183. ) |
| [11] | 屈文建, 谭光兴, 邱桃荣. 运用全1矩阵的概念格生成算法[J]. 小型微型计算机系统, 2012, 33 (3) : 558-564. ( QU W J, TAN G X, QIU T R. New algorithm of generating concept lattice using universal matrix[J]. Journal of Chinese Computer Systems, 2012, 33 (3) : 558-564. ) |
| [12] | 姚佳岷, 杨思春, 李心磊, 等. 双序渐进式概念格合并算法[J]. 计算机应用研究, 2013, 30 (4) : 1038-1040. ( YAO J M, YANG S C, LI X L, et al. Incremental double sequence algorithm of concept lattice union[J]. Application Research of Computers, 2013, 30 (4) : 1038-1040. ) |
| [13] | 徐敏政, 何宗宜, 刘亚虹, 等. 双向渐进式概念格生成算法[J]. 小型微型计算机系统, 2014, 35 (1) : 172-176. ( XU M Z, HE Z Y, LIU Y H, et al. Bidirectional incremental formation algorithm of concept lattice[J]. Journal of Chinese Computer Systems, 2014, 35 (1) : 172-176. ) |
| [14] | ZOU L G, ZHANG Z P, LONG J, et al. A fast incremental algorithm for constructing concept lattices[J]. Expert Systems with Applications, 2015, 42 (9) : 4474-4481. doi: 10.1016/j.eswa.2015.01.044 |
| [15] | 马垣, 曾子维, 迟呈英, 等. 形式概念分析及其新进展[M]. 北京: 科学出版社, 2011 : 11 -31. ( MA Y, ZENG Z W, CHI C Y, et al. Formal Concept and it's New Progress[M]. Beijing: Science Press, 2011 : 11 -31. ) |
| [16] | 梁妍, 吴杰, 马垣, 等. 基于概念格亏值的共轭对方法研究[J]. 计算机工程与设计, 2014, 35 (1) : 171-176. ( LIANG Y, WU J, MA Y, et al. Research on method of conjugate pairs based on waned values from concept lattice[J]. Computer Engineering and Design, 2014, 35 (1) : 171-176. ) |