




2. 网络与信息安全武警部队重点实验室, 西安 710086
2. Key Laboratory of Network and Information Security under Chinese People's Armed Police Force, Xi'an Shaanxi 710086, China
在当前开放的网络环境下,电子商务作为一种新型的商业运营模式,能够使买卖双方更加方便地进行各种商贸活动。但是这种“不谋面”的方式使客户和商家之间的信任受到了有用性、易用性、声誉、风险等多重因素的影响[1]。目前的电子商务平台如Amazon、Ebay、淘宝等普遍建立了信任评价机制,通过完成一次交易后客户对商家的评分来约束交易双方,从而建立信任关系。为定量描述商家的可信程度,防止评价过程中的信任欺骗,学界通过不同的信任度表示方法已经建立了许多信任模型,主要可以分为两种:基于推荐(Recommendation)的信任模型[2-3]、基于信誉(Reputation)的信任模型[4-5]。为防止恶意客户以合谋、女巫攻击等方式对商家进行夸大、诋毁或者洗白(White-washing),这些模型在使用客户的评价数据前,通常对评价中的真实评价与恶意评价进行甄别,同时对客户制定相应的评价激励机制。最终筛选量化后的评价数据才会用于计算信任度。
博弈论是研究实体间信任关系问题的有效工具。文献[6-7]基于完全理性假设,使用不完全信息动态博弈来描述客户行为的动态变化;学者已经证明,在混合策略博弈中提高惩罚措施的力度,其实无法改变被惩罚者违规概率的均衡点[8]。文献[9]在激励措施中加入动态惩罚策略,对恶意攻击者(相当于本文的恶意评价客户)采取的惩罚力度随其攻击的概率大小而变化,博弈也能够得到稳定均衡;但是精确确定攻击概率是困难的,并且这种激励方式得到的均衡点容易被少量突发的状态、策略变异所破坏,不具备鲁棒性。
在实际情况下,由于客户并不是完全理性的,其评价策略必然会受到其他客户的复杂影响。客户总是想要寻找利益最大化的评价方式,他们可能会通过交互与协作,在多次的博弈过程中不断学习试错,通过模仿中效用更高的客户策略来逐渐改进自身策略。
因此,经典博弈论并不符合现实情况,运用基于有限理性假设的演化博弈理论能够更加有效地对客户间信任关系进行建模。演化博弈论已经成功运用于无线传感器网络[10-11]和网络群体行为演化[12]等模型群体策略的预测和控制中。但是对于客户间反馈评价的信任关系,还没有成熟的演化博弈模型。
本文基于演化博弈论的方法,以复制动态(Replicator Dynamics)机制描述局中人的策略演化过程,设计演化博弈模型对电子商务中的信任模型激励机制进行动力学分析。证明了有限理性假设前提下普通激励措施的演化稳定策略(Evolutionary Stable Strategy,ESS)不存在,基于系统动力学角度提出模型改进方案,并对方案中参数设置进行讨论。使用系统动力学建模工具进行的仿真分析说明,改进的方案能够达到理想的演化稳定状态,并且这种状态具有鲁棒性,能够应对少量客户的策略突变。
1 博弈问题描述和基本假设 1.1 模型参数设置和假设条件参与者 客户集合C=(C1,C2,…,Cn),客户状态属性的集合w=(w1,w2),表示客户Ci(1≤i≤n)进行真实评价或者恶意评价。
行为策略 S=(S1,S2)是客户Cj(1≤j≤n)的行为策略集合,S1表示客户Cj信任客户Ci的评价,S2表示客户Cj不信任客户Ci的评价。
收益函数 在表示客户间的行为信任关系时,常使用信任度的进行度量,已经有文献[2-5]给出较为成熟的信任度计算方法。本文不考虑如何计算客户信任度,假设客户都已有某个信任度值,且值越高表示客户越可信。
根据现有信任模型的激励措施:系统对恶意评价的客户进行惩罚,对真实评价的客户进行奖励;客户的真实评价能够得到双方共赢的结果,而恶意客户通常能够能通过夸大或贬低的恶意评价获得其他客户的利益。
假设系统能够以100%的概率识别出客户Ci的状态:真实评价w1给予奖励αT,恶意评价w2受到-βT的处罚。假设在一个t时刻客户Ci的真实评价被Cj信任,则双方共赢均得到收益Te;Ci的恶意评价被Cj信任,则Cj遭受损失-Tl,Ci同时得到收益Tl,且Tl>Te;Cj不信任任何评价,则Cj没有收益增减。得到在t时刻不同信任策略下客户的收益矩阵如下:
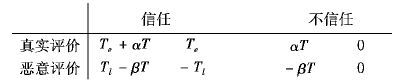
|
如果基于完全理性假设,对客户收益矩阵进行划线法可以得知,博弈有纳什均衡策略C(1,1),即客户在现有激励措施下能够进行真实评价且相互信任。下面通过演化博弈模型进行重新分析。
1.2 建立演化博弈模型定义1 复制动态。指客户的策略可以在每个时间段的演化过程中从没有差错地传给下个时间段的客户。
复制动态模型使用常微分方程来描述策略的演化[13],而微分方程在数学上具有很好的解析性质,因此复制动态成为演化博弈中最常用的一种决策机制。
常用复制动态方程为:
| ${{\dot{\theta }}_{t}}(t)={{\theta }_{t}}(t)(u({{s}_{i}},\theta (t))-\bar{u}(\theta (t),\theta (t))$ |
其中:θt(t)为个体在t时刻选择纯策略si的数量占整体的比例;u(si,θ(t))为个体选择纯策略si的期望收益;u(θ(t),θ(t))为整体的平均收益。
定义2 演化稳定策略。客户之间形成的某种即使受到少量干扰后仍能恢复到均衡的长期稳定策略。
由于演化稳定策略具有稳定性,即在此状态下客户评价状态和策略选择即使发生少量突变,最终仍会返回到该状态。
假设在评价反馈模型中选择真实评价的客户比例为x,则选择恶意评价的客户比例为1-x;选择信任策略的客户比例为y,则选择不信任策略的客户比例为1-y。
对于客户Ci,真实评价的期望收益为:
| ${{u}_{11}}=y({{T}_{e}}+\alpha T)+(1-y)\alpha T$ |
选择恶意评价的期望收益为:
| ${{u}_{12}}=y({{T}_{l}}-\beta T)-(1-y)\beta T$ |
整体平均收益为:
| ${{{\bar{u}}}_{1}}=x{{u}_{11}}+(1-x){{u}_{12}}$ |
得到客户Ci的复制动态方程:
| $\begin{align} & {{f}_{w}}(x)=x({{u}_{11}}-{{{\bar{u}}}_{1}}) \\ & =x(1-x)(y{{T}_{e}}-y{{T}_{l}}+aT+\beta T) \\ & {{f}_{w}}^{\prime }(x)=(1-2x)(y{{T}_{e}}-y{{T}_{l}}+aT+\beta T) \\ \end{align}$ |
同理得到客户Cj的复制动态方程:
| $\begin{align} & {{f}_{s}}(y)=y({{u}_{21}}-{{{\bar{u}}}_{2}}) \\ & =y(1-y)(x{{T}_{e}}+x{{T}_{l}}-{{T}_{l}}) \\ & {{f}_{s}}^{\prime }(y)=(1-2y)(x{{T}_{e}}+x{{T}_{l}}-{{T}_{l}}) \\ \end{align}$ |
根据微分方程平衡点的稳定性原理,当fw(x)、 fs(y)在对稳定状态处的函数值等于0,且f′w (x*)、 f′s (y*)小于0时的状态x是演化稳定的。
1) 令fw(x)=0,则当
2) 令fs(y)=0,当
| $x={{x}^{*}}=\frac{{{T}_{l}}}{{{T}_{e}}+{{T}_{l}}}$ | (1) |
时,有fw(y)=0。此时对于选择信任策略的客户比例y是稳定的;当x≠x*时,y=0和y=1是演化方程两个稳定解。
演化博弈系统的雅可比矩阵为:
| $\begin{align} & J= \\ & \left[ \begin{matrix} (1-2x)[y({{T}_{e}}-{{T}_{l}})+(aT+\beta T)] & x(1-x)({{T}_{e}}-{{T}_{l}}) \\ y(1-y)({{T}_{e}}+{{T}_{l}}) & (1-2y)[x({{T}_{e}}+{{T}_{l}})-{{U}_{l}}] \\ \end{matrix} \right] \\ \end{align}$ | (2) |
因为aT+βT>0,且Tl-Te>0,所以由雅可比矩阵(2):1) 客户信任策略给定时,若y>y*,fw ′(0)<0,x=0是博弈的演化稳定策略;若y<y*,fw ′(1)<0,x=1是博弈的演化稳定策略。2)客户评价状态给定时,若x>x*,fs ′(1)<0,y=1是博弈的演化稳定策略;若x<x*,fs ′(0)<0,y=0,是博弈的演化稳定策略。得到客户策略的演化博弈相位如图 1。

|
图 1 演化博弈相位图 |
图 1(a)显示了采用复制动态机制模拟的客户间策略演化的趋势。图 1(b)中5个均衡点分别表示:A(x*,y*) 为鞍点;O(0,0)表示客户均处于恶意评价状态、且不信任对方评价;B(1,0)表示客户处于真实评价状态、但不信任对方评价;C(1,1)表示客户处于真实评价状态、并信任对方评价;D(0,1)表示客户处于恶意评价状态、但信任对方评价。
在本例情况下,O(0,0)、B(1,0)、C(1,1)、D(0,1)都是不稳定均衡点,与经典博弈论建模得到的结果不符。在实际情况下,如果电子商务环境中采取信任策略客户比例较大(y>y*),由于恶意评价策略的收益更多,因此选择真实评价策略的客户比例会减少(向x=0演化);当选择真实评价策略的客户比例减少到一定程度(x<x*)时,客户采取不信任策略的收益更多,因此选择信任策略的客户比例会减少(向y=0演化)。依此类推,客户初始状态在任意区域均不能得到演化稳定策略。
3 模型改进虽然普通激励措施的应用会在短期内降低恶意评价客户数量,并使真实评价状态的客户比例增加,但长期来看由于客户恶意评价成本不高,恶意评价的高收益吸引仍然存在,恶意评价客户数量又会逐渐回升,最终导致博弈双方比例反复波动无法均衡。
从系统动力学角度来看,增强信任激励、提高交易者信任行为的收益比较优势可以促进信任的形成[14]。普通激励措施仅拉大了对客户真实评价和恶意评价的比较优势,但是并没拉开信任策略和不信任策略的比较优势。因此,在改进的激励机制中,对于客户Ci,若其真实评价被信任,则系统给予客户补偿收益Tc;若真实评价不被信任,则系统减少客户收益-Tc。客户Cj收益矩阵不作改变。得到t时刻不同信任策略下客户的收益矩阵如下:
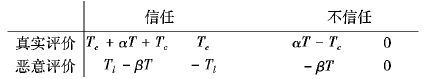
|
重新计算客户Ci演化博弈复制动态方程:
| $\begin{align} & {{f}_{w}}(x)=x({{u}_{11}}-{{{\bar{u}}}_{1}}) \\ & =x(1-x)(y{{T}_{e}}+2y{{T}_{c}}-y{{T}_{l}}+aT+\beta T-{{T}_{c}}) \\ & {{f}_{w}}^{'}(x)=(1-2x)[y({{T}_{e}}+2{{T}_{c}}-{{T}_{l}})+aT+\beta T-{{T}_{c}}] \\ \end{align}$ |
令fw(x)=0,当
| $y={{y}^{*}}=\frac{aT+\beta T-{{T}_{c}}}{{{T}_{l}}-(2{{T}_{c}}+{{T}_{e}})}$ | (3) |
时,有fw(x)=0。此时选择真实评价状态客户比例x是稳定的。
当y≠y*时,x=0和x=1是演化方程两个稳定解。
1) 当aT+βT-Tc>0,Tl-(2Tc+Te)>0时,博弈结果与未改进激励机制之前相同,无法得到演化稳定状态。
2) 当aT+βT-Tc<0,Tl-(2Tc+Te)<0时,若y>y*,fw ′(1)<0,x=1是博弈的演化稳定策略;若y<y*,fw ′(0)<0,x=0是博弈的演化稳定策略。
得到改进后的客户策略演化博弈相位图 2。图 2(a)显示了采用复制动态机制模拟的客户间策略演化的趋势。图 2(b)中O(0,0)、C(1,1)两个点为博弈的演化均衡点;B(1,0),D(0,1)为不稳定平衡点。

|
图 2 改进后的演化博弈相位图 |
客户的初始状态若位于ODAB区域,则将演化到O(0,0)点,即处于恶意评价状态、且不信任对方评价;若位于DABC区域,则将演化到C(1,1)点,即处于真实评价状态、并信任对方评价。这种演化稳定状态具有鲁棒性,即使客户的评价策略由于各种因素发生少量突变,也能够返回到该状态。
4 实验仿真与分析本文采用NetLogo平台的系统动力学建模工具对演化博弈模型进行实验仿真。此工具能够对群体行为进行编程,便于观察不同类型客户数量随着博弈进行的变化规律。
图 3所示的NetLogo系统动力学流程图由四类元素构成:存量(Stock)、变量(Variable)、流(Flow) 和连接(Link)。存量trust-stra和true-evo分别表示真实评价客户数量和信任策略客户数量,即需要观察的行为群体。根据收益矩阵中的数据,设置客户比例x、y,复制动态方程fx、fy四个变量来模拟复制动态的过程。连接把来自变量或存量的数值传送到一个存量或流,由流的输入和输出来观察客户数量的变化。add-true-evo和sub-true-evo表示真实评价客户数量的增减,add-trust-stra和sub-trust-stra表示信任策略客户的增减。客户在初始时刻随机选择状态、策略,而后依据t时刻博弈的收益,通过学习和模仿来确定 t+1 时刻选择的状态和采取的策略。

|
图 3 系统动力学流程 |
文献[15]是采取收集兴趣群组交互信息的方式建立了一种基于信誉的信任模型(Interest Group based Trust model,IGTrust)。该模型采用了普通激励措施即正面交互则得到收益,负面交互带来损失。部分实现了IGTrust的激励措施与本文改进的激励措施进行对比,保留其核心部分即收益率和损失率,收益率相当于本文信任度与奖励因子的乘积,损失率相当于信任度与惩罚因子的乘积。不考虑交易信息量、折扣因子和时间维度等辅助参数,这并不影响实验的定性分析。
在一般信任模型中,信任度取值范围通常为[0,1],本文将信任度范围放大100倍取整到[0,100],此方式与IGTrust相似并方便NetLogo值的计算。假设系统中客户总数为1 000,初始可信度T=50,恶意评价收益Tl=20,共赢收益Te=10,补偿收益Tc=15。取值满足1.1节的假设条件:
| $\left\{ \begin{align} & {{T}_{l}}>{{T}_{e}} \\ & {{T}_{l}}-(2{{T}_{c}}+{{T}_{e}})<0 \\ & aT+\beta T-{{T}_{c}}<0 \\ \end{align} \right.$ |
为了说明改进的激励措施所得到演化稳定状态的鲁棒性,对客户的评价策略采取概率为1%的随机变异,即进行评价的客户可能由于各种因素而改变原有策略。其余参数设置如表 1所示。
| 表 1 演化博弈参数 |
图 4(a)坐标横轴表示博弈次数t,纵轴为选择不同策略的客户数量,α=0.05,β=0.12。IGTrust使用的普通激励措施由系统动力学分析结果显示:只要客户数量初始值与鞍点均衡值不同,博弈双方的状态、策略选择就会不会稳定。随着博弈次数和时间的增加,不同评价状态和信任策略客户比例周期性变化,不存在ESS。

|
图 4 普通激励措施的客户数量变化 |
对α和β值进行调整,即提升奖惩力度,使α=0.09,β=0.14。图 4(b)显示相同的博弈次数中,选择真实评价和信任策略客户数量周期性变化更快。说明加大奖惩力度能够在更短周期内改变客户的策略选择,但是长期来看,两种客户的数量仍然随博弈的进行不断变化,不存在ESS,并不能得到客户一直进行真实评价且相互信任的稳定状态。
4.2 改进激励措施仿真 4.2.1 参数值选取选择真实评价的客户比例x=0.5<0.66,选择恶意评价的客户比例y=0.35<0.425,模拟电子商务评价环境整体情况不好,即真实评价较少、客户间大多不愿意相互信任的情况下。结果如图 5,选择真实评价客户和和信任策略的客户数量都降低到0,博弈将最终演化到O(0,0)的均衡。说明改进的方案必须严格参数设置,降低博弈鞍点值,以得到想要的演化稳定状态。根据式(2)和(3),增大α、β及Tc的值,即加大奖惩力度、提高补偿收益能够有效降低y鞍点值使y*=0.175<0.35,从而使模型能够达到理想的演化稳定状态。同理,如果增加对选择信任策略用户的补偿,也能够有效降低x鞍点值。

|
图 5 参数值取鞍点以下的客户数量变化 |
调整参数和策略变异概率之后的客户数量变化如图 6所示。之前的实验客户策略变异概率为1%,经多次测试实验,本文如图 6所示将将概率值提升到7%,仍可以保证模型达到演化博弈状态。同时调整奖惩因子使α=0.09,β=0.14。当x、 y中有一个数不小于而另一个数大于鞍点值时,选择真实评价客户和信任策略的客户数量都增加到1 000,博弈将最终演化到客户进行真实评价并且相互信任的均衡。

|
图 6 调整策略变异概率后的客户数量变化 |
信任模型是电子商务中客户和商家建立信任的重要技术之一,引导客户进行真实评价,建立客户能够相互信任的良好环境是电子商务中信任评价激励机制是否成功的关键。本文基于演化博弈理论反映了客户间不同策略选择的收益得失,体现了客户行为不完全理性及相互参照模仿的特点;并应用NetLogo的动力学分析模块对现有的信任模型激励措施进行了分析改进,得到了演化稳定策略,有效地保证客户能够达到真实评价并且相互信任的稳定状态。在该状态中,绝大多数客户进行正常评价从而真实反映商家的信任度,客户间相互信任从而促进客户评价能够得到更广泛传播和合理运用,对收集电子商务中客户对商家质量的真实感受,提升信任模型度量准确性具有积极意义。
| [1] | 甘早斌, 曾灿, 马尧, 等. 基于信任网络的C2C电子商务信任算法[J]. 软件学报, 2015, 26 (8) : 1946-1959. ( GAN Z B, ZENG C, MA Y, et al. C2C e-commerce trust algorithm based on trust network[J]. Journal of Software, 2015, 26 (8) : 1946-1959. ) |
| [2] | LI F Y, ZHAO S, ZHOU J. Research on dynamic trust model based on recommendation trust iteration[J]. International Journal of Computing Science and Mathematics, 2016, 7 (1) : 235-244. |
| [3] | MORADI P, AHMADIAN S. A reliability-based recommendation method to improve trust-aware recommender systems[J]. Expert Systems with Applications, 2015, 42 (21) : 7386-7398. doi: 10.1016/j.eswa.2015.05.027 |
| [4] | MARMOL F G, KUHNEN M. Reputation-based Web service orchestration in cloud computing:a survey[J]. Concurrency & Computation Practice & Experience, 2015, 27 (7) : 2390-2412. |
| [5] | TIAN B, HAN J, LIU K. Closed-loop feedback computation model of dynamical reputation based on the local trust evaluation in business-to-consumer e-commerce[J]. Information, 2016, 7 (1) : 1-21. doi: 10.3390/info7010001 |
| [6] | FREY V, BUSEKENS V, RAUB W. Embedding trust:a game-theoretic model for investments in and returns on network embeddedness[J]. Journal of Mathematical Sociology, 2015, 39 (1) : 39-72. doi: 10.1080/0022250X.2014.897947 |
| [7] | 陈亚睿, 田立勤, 杨扬. 云计算环境下基于动态博弈论的客户行为模型与分析[J]. 电子学报, 2011, 39 (8) : 1818-1823. ( CHEN Y R, TIAN L Q, YANG Y. Model and analysis of user behavior based on dynamic game theory in cloud computing[J]. Acta Electronica Sinica, 2011, 39 (8) : 1818-1823. ) |
| [8] | DONG-HWAN K, DOAHOON K. A system dynamics model for a mixed-strategy game between police and driver[J]. System Dynamics Review, 1997, 13 (1) : 33-52. doi: 10.1002/(ISSN)1099-1727 |
| [9] | 朱建明, 宋彪, 黄启发. 基于系统动力学的网络安全攻防演化博弈模型[J]. 通信学报, 2014, 35 (1) : 54-61. ( ZHU J M, SONG B, HUANG Q F. Evolution game model of offense-defense for network security based on system dynamics[J]. Journal on Communications, 2014, 35 (1) : 54-61. ) |
| [10] | JIANG G, SHEN S, HU K, et al. Evolutionary game-based secrecy rate adaptation in wireless sensor networks[J]. International Journal of Distributed Sensor Networks, 2015, 11 (3) : 975454. |
| [11] | CHEN Z, QIAO C, QIU Y, et al. Dynamics stability in wireless sensor networks active defense model[J]. Journal of Computer & System Sciences, 2014, 80 (8) : 1534-1548. |
| [12] | 王元卓, 于建业, 邱雯, 等. 网络群体行为的演化博弈模型与分析方法[J]. 计算机学报, 2015, 38 (2) : 282-300. ( WANG Y Z, YU J Y, QIU W, et al. Evolutionary game model and analysis methods for network group behavior[J]. Chinese Journal of Computers, 2015, 38 (2) : 282-300. ) |
| [13] | TATLO P, JONKER L. Evolutionarily stable strategies and game dynamics[J]. Mathematical Biosciences, 1978, 40 (2) : 145-156. |
| [14] | 李征. 基于ESS均衡的电子商务信任模型[J]. 计算机应用, 2008, 28 (8) : 2173-2176. ( LI Z. Trust model in e-commerce based on ESS equilibrium[J]. Journal of Computer Applications, 2008, 28 (8) : 2173-2176. ) |
| [15] | 田春岐, 黄震华, 邹仕洪. 构建自组网络中基于兴趣群组的激励机制[J]. 电子学报, 2015, 43 (12) : 2466-2469. ( TIAN C Q, HUANG Z H, ZOU S H. Building an interest group based incentive mechanism for Ad Hoc networks[J]. Acta Electronica Sinica, 2015, 43 (12) : 2466-2469. ) |